9.4.4.1 توضیحات #
شما با استفاده از الگو pooling می توانید برای استفاده مجدد یا مدیریت تعداد ثابتی از منابع مانند : کانکشن های دیتابیس یا مجموعه ای از گوروتین های کارگر استفاده کنید. از کانال برای برقراری ارتباط بین مجموع منابع استفاده می شود.
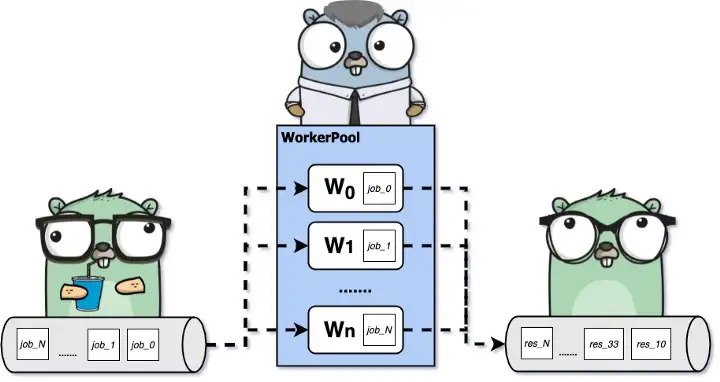
9.4.4.2 دیاگرام #
9.4.4.3 نمونه کد #
1package main
2
3import (
4 "fmt"
5)
6
7func main() {
8 jobs := make(chan int, 100)
9 results := make(chan int, 100)
10
11 // Start 3 worker goroutines
12 for w := 1; w <= 3; w++ {
13 go worker(w, jobs, results)
14 }
15
16 // Send 5 jobs to the worker pool
17 for j := 1; j <= 5; j++ {
18 jobs <- j
19 }
20 close(jobs)
21
22 // Collect the results
23 for a := 1; a <= 5; a++ {
24 fmt.Println(<-results)
25 }
26}
27
28func worker(id int, jobs <-chan int, results chan<- int) {
29 for j := range jobs {
30 fmt.Println("worker", id, "processing job", j)
31 results <- j * 2
32 }
33}
1$ go run main.go
2worker 3 processing job 1
3worker 3 processing job 4
4worker 3 processing job 5
5worker 1 processing job 2
62
78
810
94
10worker 2 processing job 3
116
فرض کنید ما ۱۰۰ تسک داریم که قرار است این تسک ها را بین کارگرها تقسیم کنید و در نهایت نتیجه را از طریق کانال دریافت کنیم.
حال ما ۲ تا کانال ایجاد می کنیم با بافر ۱۰۰ تایی به نام jobs و results که قرار است ۱۰۰ تسک بواسطه این کانال ها ارسال و دریافت شود.
ما یک تابع worker داریم که jobs را دریافت میکند از طریق کانال و پس از عملیات نتیجه را داخل کانال results میفرستد.
- کانال jobs از نوع فقط دریافتی است
- کانال results از نوع فقط ارسال است
حال با فرض اینکه بطور موازی ۳ تا کارگر داریم که این تسک ها را دریافت می کنند و پس از انجام نتیجه را میفرستند. برای اینکه ۳ تا کارگر را ایجاد کنیم از حلقه استفاده میکنیم و تابع worker را داخل گوروتین قرا می دهیم و پس از آن jobs و results را به عنوان پارامتر ورودی به هر ورکر می دهیم.
در ادامه یک حلقه ایجاد می کنیم ۵ تا کار (job) داریم قرار است هرکدام از کارگرها توانست انجام دهد و ما کارها را از طریق کانال میفرستیم.
در نهایت یک حلقه دیگر داریم که این job ها را از طریق کانال results دریافت می کنیم و پس آن چاپ می کنیم.
9.4.4.4 کاربردها #
- تقسیم کارهای پردازشی : شما با استفاده از این الگو می توانید پردازش یک داده سنگین را بین چند کارگر تقسیم کنید و بطور موازی این داده های سنگین در کمترین زمان پردازش می شود و جلو هزینه و سربار را میگیرد و باعث افزایش و بهبود عملکرد شود.